Real-World Microservice Design: Part 1 — Persistence & Retrieval Patterns
The use case is relatively simple. Hypothetical scenario. Let’s rewind the clock back to 1998 — prime BlockBuster era. Those of you that remember, BlockBuster was a store that you entered, browsed the movie selection spread across dozens of aisles in the store and then pay a clerk some money to take the movie home with a promise to bring it back in 2–3 days time — after dutifully rewinding the tape.
Imagine yourself in 1998. Now imagine all the glorious BlockBusters of the world sprinkled across the country. Each providing such a convenient way for people to rent their favorite movies to watch in the convenience of their homes. But what happens if the BlockBuster didn’t have the movie you want to rent? The 10 minuie drive to the store would have been all in vain.
Now let’s imagine a better 1998 — a more tech savvy 1998 where each of these BlockBuster locations publish their inventory on their own location specific web site. Great, right? Very high tech. If we wanted to see what the current inventory for any given BlockBuster all we’d have to do is Google Search their web site (a very 1998 thing to do) and download their inventory in CSV format to see if they have the movie we want. But what if they don’t have the movie we want? Well, we’d have to find another BlockBuster’s web site and download their CSV file to check their inventory for the night. This can get labor intensive fast.
You’re probably wondering where I am going with this. Well I wanted to introduce the use case for a Microservice Design of mine without divulging the actual use case. So I have stealthily replaced the actual use case with this fictional version of 1998 with tech-forward BlockBusters.
The big challenge is that in order to find the movie we want we’d have to start looking up and downloading quite a large number of CSV files from quite a large number of BlockBuster stores.
Eureka! I’ll just build a web site that does this for you!
Let’s assume for a moment that I have already done the difficult task of collecting every BlockBuster location in the world’s web site into a database. Also in this database is the URL to the CSV file that contains that BlockBusters inventory. Each of these tech-savy BlockBusters will update their inventory on a nightly basis. All I have to do is download the files, parse them and create (or update) records in my database to specify which BlockBuster location has which movies.
Let’s start be evaluating the responsibilities of the system. These will help us evolve the boundaries between services. We know we have a list of stores, each with their own URL where they update their inventory for us. We know we need to download that URL and process the data. The important data we want to capture is the movies that each store has. Immediately this brings into focus, three bounded contexts:
- BlockBuster Store
- Inventory Downloader
- Movie Inventory
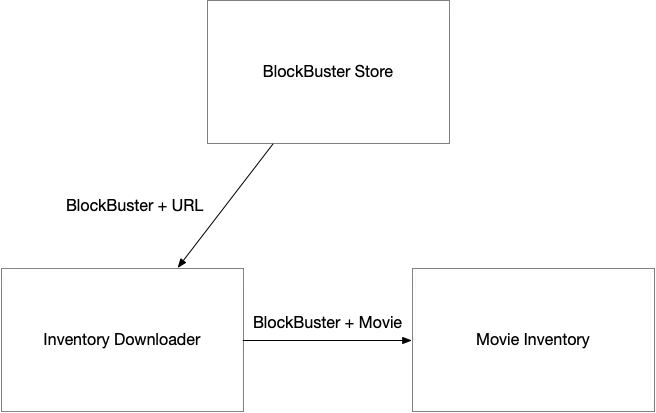
First we the concept of a BlockBuster Store. There are many of these — each has specific data that represents a store. Key pieces of information for our use case are the Store Name, Location and the URL for the machine readable file. This is our first Entity: the BlockBuster Store.
An important entity like this is what I refer to as the “Nouns” of the system. They represent the nouns within the system’s model. The model seeks to represent some real world activity by capturing state and manipulating that state (moving from one state to another) through actions or the “Verbs” of the system. Each Microservice will maintain one or more “Nouns” and facilitate the relevant “Verbs” associated with that noun.
 Noun-Centric Microservices usually facilitate Retrieval and Persistence
Noun-Centric Microservices usually facilitate Retrieval and Persistence
Whenever you have an important entity or noun its often the case that simply saving and retrieving those entities is a major use case. They often drive the User Interface in a meaningful way or they maintain state that other Microservices contribute to. Both of those access modes — Retrieval and Persistence — need to be significantly unpacked.
Retrieval
Retrival is just about getting data back after it was saved. So in many ways we are starting at the end here. It may seem simple but retrieval can be facilitated in many different ways — each with different user experience and implementation patterns, alignment with different database and storage options, and performance and scale implications.
Read
First and most apparent is the “Read” or “Get” where you access a single instance of the entity using its primary key — an integer, GUID or whatever that might be.
List
Next is when you want to return a list of the entity. This could be an unfiltered “List All” or it could be listing the entities that match specific discrete categories like “List Where X = Y”. This may seem like we are getting dangerously close to the next retrieval mechanism — Query — but I assure you, Query is absolutely its own thing. The key difference is List filters based on discrete attribute(s) and is a well-known path. Query is distinct in that it is un-opinionated and leaves the indices, columns or attributes to use when matching entities up to the client.
Query
As mentioned, Query is when you leave it up to the user to specify the attributes and indices they want to filter upon. This is often done using an object graph to describe the filter. This object graph will have filter criteria for all possible columns and attributes with all (or most) left optional allowing the user to customize the method by which they filter the entities. OData and GraphQL are implementations of this methodology.
Search
This is an even more advanced form of search where we through the structured query mechanism out the window. This is like going to Google and punching in whatever your heart desires into a single text box and seeing what comes back. In addition to the major change in the User Experience, this approach requires a fundamentally different implementation behind the scenes.
As we can see, there are many different methods for performing retrieval on entities or the Nouns of our system.
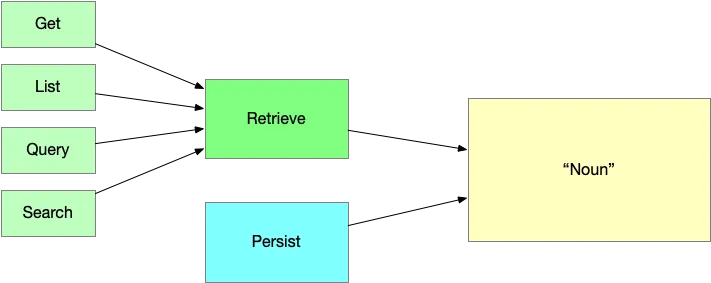 Retrieval can be broken up into four use cases: Get, List, Query and Search
Retrieval can be broken up into four use cases: Get, List, Query and Search
Persistence
When designing your Microservice, one of the key architectural decisions you’ll face is whether your entities should be mutable or immutable. This choice not only influences how you manage state and data integrity over time but also directly impacts your persistence strategy.
CRUD
At the heart of mutable persistence lies the CRUD model — Create, Read, Update, and Delete. Despite what its seemingly disparaging acronym might suggest, CRUD remains a time-tested framework for handling entity lifecycles. This approach allows you to generate new entities, modify existing ones, and remove them when necessary. By operating under a mutable paradigm, each entity is endowed with a stable unique identifier that persists even as its associated data evolves over time. This model is especially effective in scenarios where data changes are frequent and the system’s state must reflect real-time updates. Good Fit: eCommerce Product Catalog Enterprise Line-of-Business Application Avoid If: Data is required to be completely immutable or if you need a full audit trail
Drop-Create
On the other side of the spectrum, we have immutable patterns, beginning with Drop-Create. This method is ideal when your entity can be effortlessly re-created from scratch, such as when it represents configuration data that the end user customizes from a template. Instead of updating a record in place, you drop the existing entity and create a new version, ensuring that each iteration stands on its own without retroactively altering history. This strategy not only simplifies rollback and auditing processes but also reinforces the principle of immutability by treating each version as a distinct, immutable snapshot of the entity’s state at a given moment.
Good Fit:
- User Profile
- Configuration Settings Avoid If:
- Data has complex interdependencies or state that cannot be re-generated from scratch
Append-Only
Another form of immutable persistence is the Append-Only approach. Here, rather than replacing or overwriting data, every change to an entity results in a new record being appended to the historical log. This method is particularly advantageous when you need to maintain a complete audit trail of all changes over time. When retrieving the current state of an entity, you typically perform a “TOP 1” select on the primary key (while sorting by the Created Time Stamp), ensuring that you always work with the latest version while still preserving a full history of past states. This not only provides transparency but also allows for powerful analytics and debugging capabilities, as you can trace the evolution of an entity through every discrete change.
Good Fit:
- Financial Systems that need a Transaction Ledger
- Patient Medical Records Avoid If:
- High throughput transactional systems, performance and cost overhead of querying across the ages will take its toll
Event Sourcing
Another immutable persistence strategy, in this approach, every change to an entity is recorded as an event rather than a state change. These events serve as the source of truth, and the current state is derived by replaying the sequence of events. Although event sourcing shares similarities with an append-only approach, it adds a rich layer of business context and can be seamlessly paired with Command Query Responsibility Segregation (CQRS) to optimize read and write operations.
Good Fit:
- Customer Support Ticket Lifecycle Avoid If:
- High throughput transactional systems, performance and cost overhead of generating aggregates and manifest views will take its toll.
Conclusion
That’ its! Those are quite a few options. Of course, each option has many implementation options and directions the design can go — including what underlying database or storage mechanism to use to store data. But we’ve established a good foundation for evaluating each service’s data retrieval and persistence strategy.
Up next, I’ll look into each of the bounded contexts I’ve identified and how these approaches might apply. I’ll walk you through my thinking as I hope to ensure that each leverages the most appropriate pattern to balance performance, auditability, and ease of state management.