OpsWorks + Auto-scaling Windows Stacks
AWS has multiple ways of enabling Auto-scaling of EC2 instances. Two of which are Auto-Scaling Groups and OpsWorks.
When setting up a stack in OpsWorks you’ll notice that you can add Load-based instances to scale the stack beyond the fixed instances you establish. The scale configuration that you specify on the below screen should be reminiscent of what you are familiar with Auto-Scaling Groups.

When creating a stack of Windows you might notice a slightly different experience. While the scaling parameters and CloudWatch Alarms are identical. You’ll notice that the “Base on Layer averages” section is completely missing. This might freak you out at first and make you think auto-scaling is not possible using OpsWorks for Windows-based instance stacks but that’s what the “Based on Amazon CloudWatch alarms” section is for.

You can add one or many CloudWatch metrics as scale up and scale down triggers.
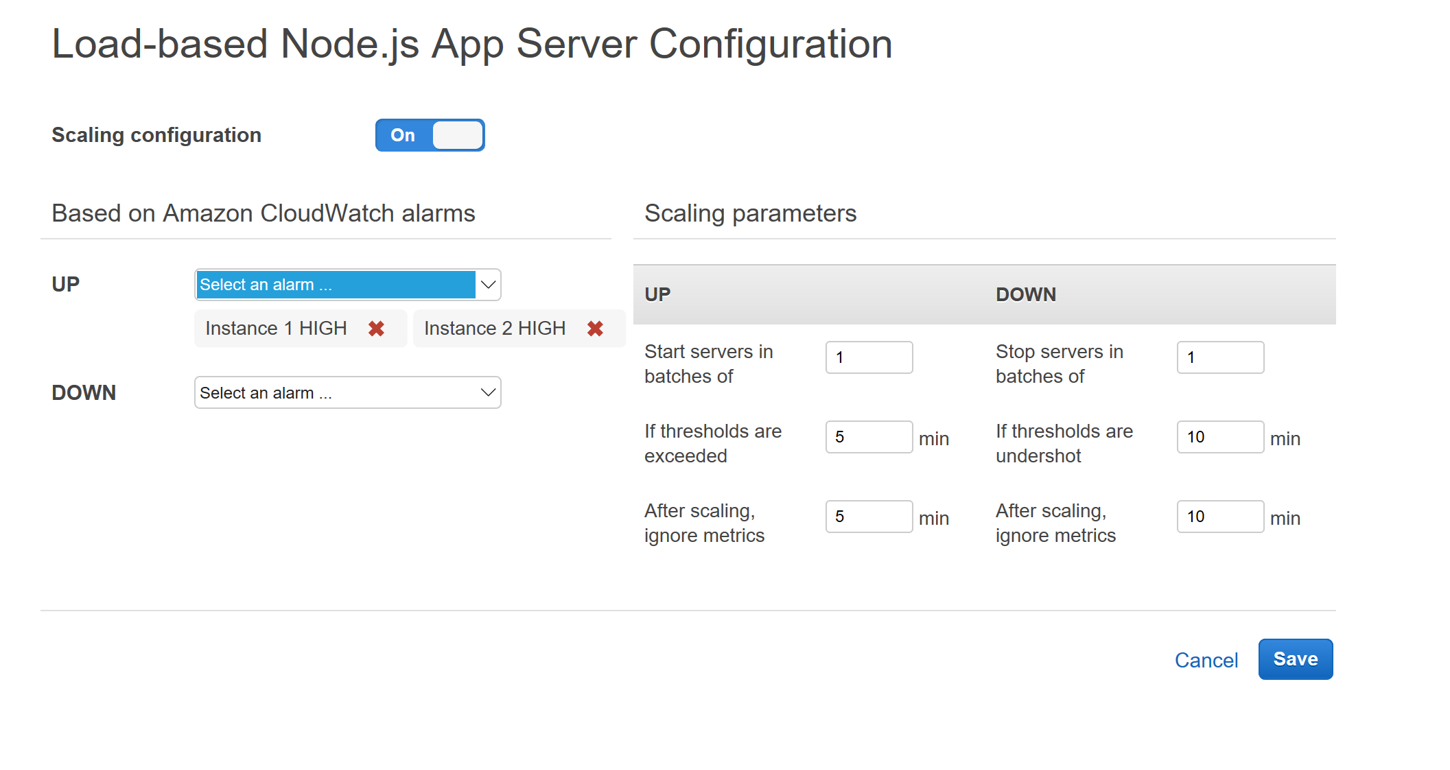
By applying some smartly configured CloudWatch alarms we can reproduce the same metrics that are available in the “Based on Layer averages” section from the Linux Stack Scaling Configuration screen. Now that we have auto-scaling enabled we can put some load on the stack and see the auto-scaling work.
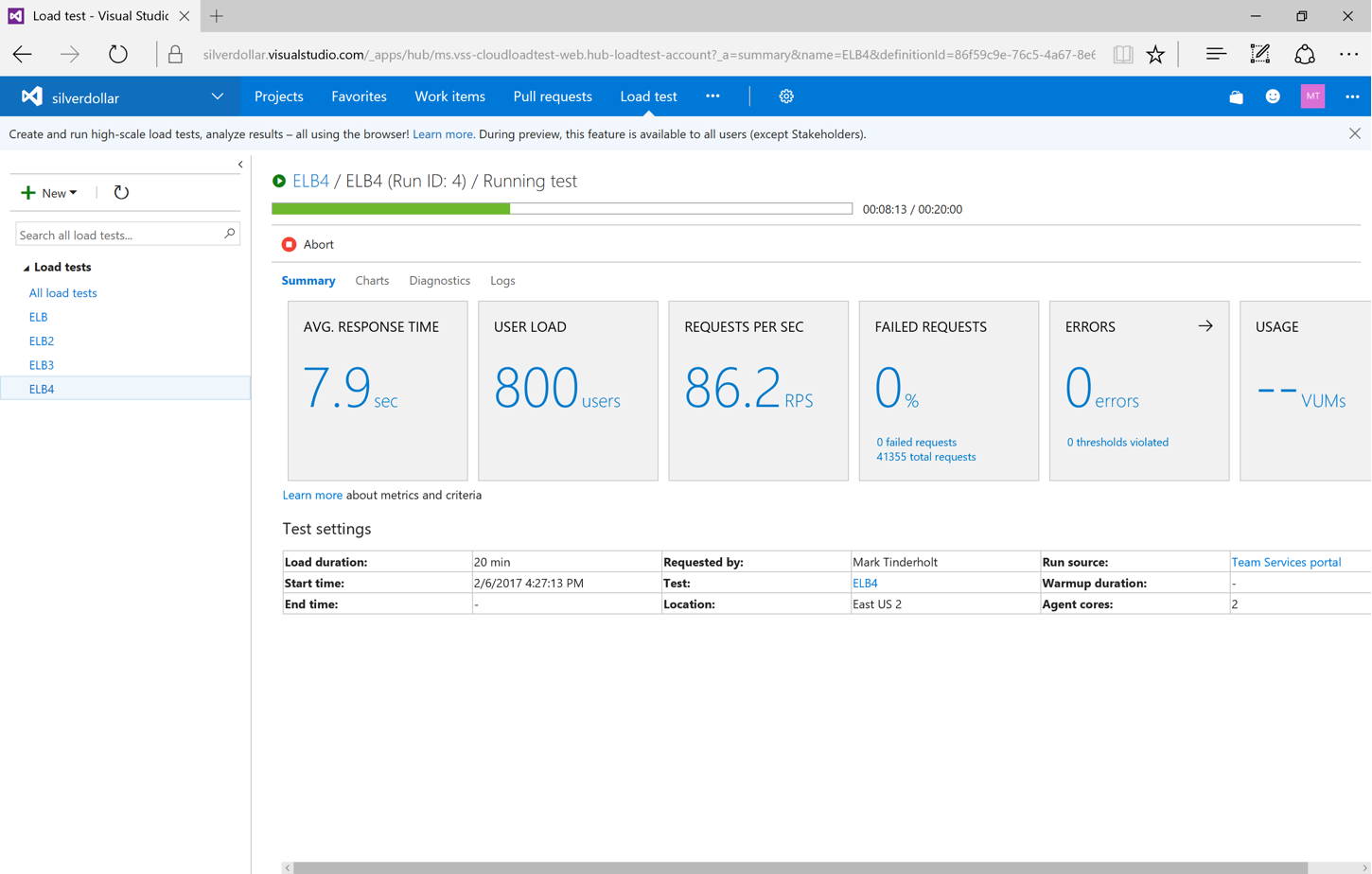
After playing several different load scenarios with 50, 100, 400 and 800 users I finally caused the fixed instances to hit the CPU Utilization metric that I configured for the CloudWatch alarms.
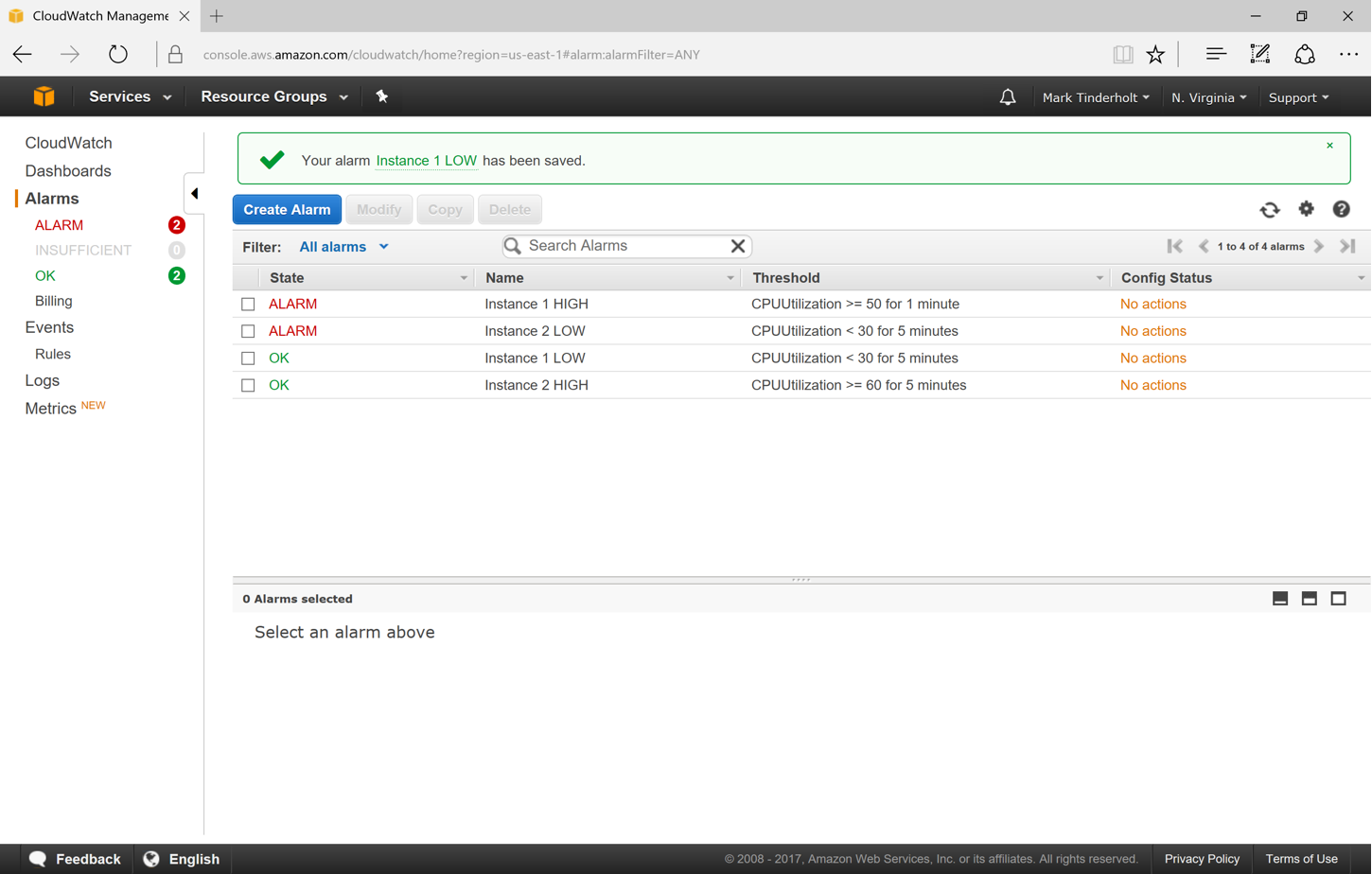
Now that the alarm is triggered we can see the first load-based instance kicked off with the boot process rolling.
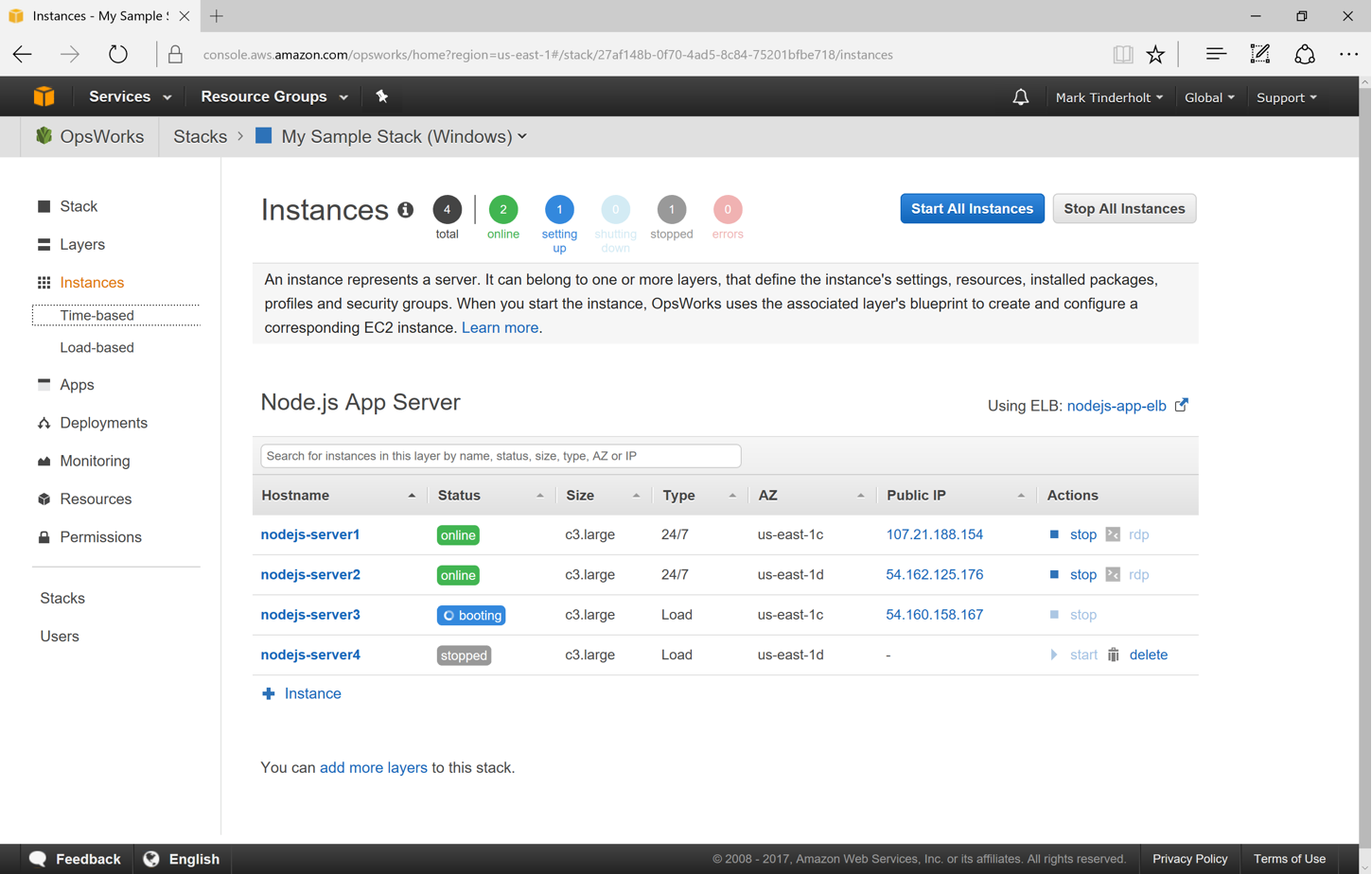
So we effectively setup auto-scaling with OpsWorks and Windows EC2 instances. However, what’s the difference between those Layered Metrics we used out-of-the-box for the Linux stack and the CloudWatch metrics we used for the Windows stack?
Essentially, it comes down to where we draw the working average CPU utilization. Will an average of a sample set effectively model the utilization of the whole? Or do we require an average of the whole? If we have n total running instances within the stack, k fixed instances and n load-based instances. We know that Layered Metrics draw from n instances, while our CloudWatch metrics create a union of independent variables from k instances. Assuming that our Elastic Load Balancer is distributing load evenly across all instances P(n) = P(k), or the probability of n is equal to the probability of k. Thus, using the CloudWatch metrics to determine when to scale should be equivalent to using the Layered Metrics available in Linux Stacks.