Ditch Unnecessary Abstractions, Embrace a Direct Hands-On Approach to automating Azure OpenAI with Terraform
This article explores the practicalities of integrating your own data — stored in Azure Blob Storage — into an Azure OpenAI model. While Microsoft’s Azure Developer CLI (azd) aims to simplify the deployment of AI-powered solutions, this article takes a critical look at whether it truly reduces complexity or just abstracts it. We’ll examine what’s really going on with the underlying infrastructure components by looking at the Bicep and PowerShell that makes it happen and the challenges posed by missing a way to effectively provision Azure Search Data Plane resources. Finally, I’ll explore how Terraform provides a cleaner, more maintainable alternative.
By the end, you’ll have a deeper understanding of the trade-offs involved in different automation approaches and how to make informed choices for your own deployments.
The Codebase
My goal was to take a set of PDFs and use them within an Azure OpenAI service. Fortunately, I stumbled upon a promising GitHub project: Azure-Samples/openai-chat-your-own-data, an infrastructure template designed to provision all necessary Azure resources for a Retrieval-Augmented Generation (RAG) AI solution.
While the project was well-structured and effective, I quickly realized that it leaned heavily on azd (Azure Developer CLI). While azd is marketed as a way to simplify the deployment of Azure solutions, I found that it added an unnecessary layer of abstraction. The tool boasts the ability to initialize an Azure environment with just three commands:
azd init --template openai-chat-your-own-data
azd auth login
azd up
However, anyone familiar with Terraform or even Bicep knows that deploying infrastructure using az deployment group create or terraform apply is not particularly difficult. The underlying solution still consisted of Bicep templates and PowerShell scripts, making me wonder if azd truly added value beyond an initial onboarding experience.
Breaking Down the AZD / Bicep / PowerShell Solution
Underneath the azd abstraction, the deployment relied on Bicep to provision Azure resources and PowerShell to configure the Azure Search service’s data plane components. Specifically, the PowerShell scripts were necessary to create:
- Index (Defines the structure of data stored in Azure Search)
- Data Source (Connects Azure Search to Blob Storage)
- Indexer (Schedules and processes the data into the search index)
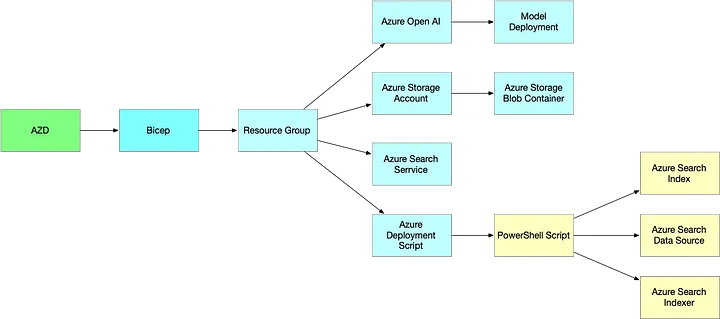 AZD / Bicep / PowerShell Solution Structure
AZD / Bicep / PowerShell Solution Structure
The PowerShell script executed inside an Azure deployment script resource, running within a temporary Azure container. The script retrieved an Access Token, built JSON payloads, and made REST API calls to the Azure Search endpoint. For example, the command below creates the search index:
Invoke-WebRequest `
-Method 'PUT' `
-Uri "https://$searchServiceName.search.windows.net/indexes/$($indexDefinition['name'])?api-version=$apiversion" `
-Headers $headers `
-Body (ConvertTo-Json $indexDefinition)
While the approach was functional, it felt unnecessarily complex. The need for PowerShell and REST API calls indicated that Azure Search’s data plane could not be provisioned using Bicep alone, but the reliance on an embedded PowerShell script inside a Bicep deployment script felt cumbersome.
Overcoming the Missing Azure Search Data Plane
The PowerShell script executed inside an Azure deployment script resource, running within a temporary Azure container. The script retrieved an Access Token, built JSON payloads, and made REST API calls to the Azure Search endpoint. For example, the command below creates the search index:
$indexDefinition = @{
'name' = $searchIndexName;
'fields' = @(
@{ 'name' = 'id'; 'type' = 'Edm.String'; 'key' = $true; 'retrievable' = $true; 'filterable' = $true; 'sortable' = $true; 'facetable' = $false; 'searchable' = $false },
@{ 'name' = 'content'; 'type' = 'Edm.String'; 'searchable' = $true; 'retrievable' = $true; 'sortable' = $false; 'filterable' = $false; 'facetable' = $false; 'key'= $false },
@{ 'name' = 'filepath'; 'type' = 'Edm.String'; 'searchable' = $false; 'retrievable' = $true; 'sortable' = $false; 'filterable' = $false; 'facetable' = $false; 'key'= $false },
@{ 'name' = 'title'; 'type' = 'Edm.String'; 'searchable' = $true; 'retrievable' = $true; 'sortable' = $false; 'filterable' = $false; 'facetable' = $false; 'key'= $false },
@{ 'name' = 'url'; 'type' = 'Edm.String'; 'searchable' = $false; 'retrievable' = $true; 'sortable' = $false; 'filterable' = $false; 'facetable' = $false; 'key'= $false },
@{ 'name' = 'chunk_id'; 'type' = 'Edm.String'; 'searchable' = $false; 'retrievable' = $true; 'sortable' = $false; 'filterable' = $false; 'facetable' = $false; 'key'= $false },
@{ 'name' = 'last_updated'; 'type' = 'Edm.String'; 'searchable' = $false; 'retrievable' = $true; 'sortable' = $false; 'filterable' = $false; 'facetable' = $false; 'key'= $false }
);
}
# https://learn.microsoft.com/rest/api/searchservice/create-index
Write-Host "https://$searchServiceName.search.windows.net/datasources/$($indexDefinition['name'])?api-version=$apiversion"
Invoke-WebRequest `
-Method 'PUT' `
-Uri "https://$searchServiceName.search.windows.net/indexes/$($indexDefinition['name'])?api-version=$apiversion" `
-Headers $headers `
-Body (ConvertTo-Json $indexDefinition)
This script defines the structure for how files are stored in Azure Blob Storage. The content field is marked as searchable=true, ensuring that Azure Search can process the stored data efficiently.
Next, the script provisions the Data Source, which connects Azure Search to the Azure Storage Account:
$dataSourceDefinition = @{
'name' = 'azureblob-datasource';
'type' = 'azureblob';
'container' = @{
'name' = $dataSourceContainerName;
};
'credentials' = @{
'connectionString' = $dataSourceConnectionString
};
}
# https://learn.microsoft.com/rest/api/searchservice/create-data-source
Invoke-WebRequest `
-Method 'PUT' `
-Uri "$uri/datasources/$($dataSourceDefinition['name'])?api-version=$apiversion" `
-Headers $headers `
-Body (ConvertTo-Json $dataSourceDefinition)
This step establishes the connection between the Azure Search service and the designated Blob Storage container. Notably, this approach requires a connection string, which implies the use of access keys.
Finally, the Indexer is created to scan the data source and populate the search index:
$indexerDefinition = @{
'name' = 'azureblob-indexer';
'targetIndexName' = $searchIndexName;
'dataSourceName' = 'azureblob-datasource';
'schedule' = @{ 'interval' = 'PT5M' };
}
# https://learn.microsoft.com/rest/api/searchservice/create-indexer
Invoke-WebRequest `
-Method 'PUT' `
-Uri "$uri/indexers/$($indexerDefinition['name'])?api-version=$apiversion" `
-Headers $headers `
-Body (ConvertTo-Json $indexerDefinition)
The Indexer essentially ties the Index and Data Source together while specifying a scan schedule.
Rewriting the Solution in Terraform
To simplify the process, I decided to eliminate azd entirely and replace the entire infrastructure definition with Terraform. Since all the required resources were already supported in Terraform’s azurerm provider, converting the Bicep templates was straightforward.
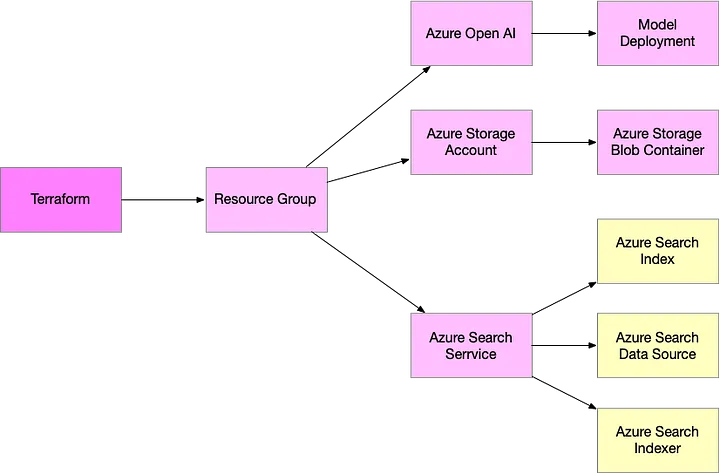
However, the Azure Search Index, Data Source, and Indexer resources were not supported directly in Terraform. Instead of using the deployment script method with PowerShell, I opted to use the Terraform HTTP provider to make REST API calls directly to Azure Search. The first step was obtaining an Azure authentication token using Terraform’s external provider:
data "external" "azure_auth_token" {
program = ["sh", "-c", <<EOT
az account get-access-token --resource https://search.azure.com --query "{access_token: accessToken}" --output json
EOT
]
}
locals {
auth_token = data.external.azure_auth_token.result["access_token"]
}
Rather than writing a PowerShell script to generate JSON payloads, I used Terraform locals to structure the index definition:
locals {
search_index_name = "${var.environment_name}index"
index_definition = {
name = local.search_index_name
fields = [
{ name = "id", type = "Edm.String", key = true, retrievable = true, filterable = true, sortable = true },
{ name = "content", type = "Edm.String", searchable = true, retrievable = true },
{ name = "filepath", type = "Edm.String", retrievable = true },
{ name = "title", type = "Edm.String", searchable = true, retrievable = true },
{ name = "url", type = "Edm.String", retrievable = true },
{ name = "chunk_id", type = "Edm.String", retrievable = true },
{ name = "last_updated", type = "Edm.String", retrievable = true }
]
}
}
Instead of running PowerShell scripts inside an Azure container, I directly invoked the Azure Search API using Terraform’s http provider:
data "http" "create_index" {
url = "${local.search_endpoint}/indexes/?api-version=${local.search_api_version}"
method = "POST"
request_headers = {
Authorization = "Bearer ${local.auth_token}"
Content-Type = "application/json"
}
request_body = jsonencode(local.index_definition)
depends_on = [
azurerm_search_service.main,
azurerm_role_assignment.search_service_contributor
]
}
I setup some extra locals to make it easier to build the REST API URL.
locals {
search_endpoint = "https://${azurerm_search_service.main.name}.search.windows.net"
search_api_version = "2024-07-01"
}
Terraform’s Efficiency and Future Potential
One of the most striking improvements in the Terraform solution was the significant reduction in lines of code — 522 lines in the original Bicep/PowerShell solution compared to just 220 lines in Terraform.
This was largely due to Terraform’s flexibility in utilizing additional providers, such as the http and external providers, which allowed me to work around the lack of native support for Azure Search data plane resources.
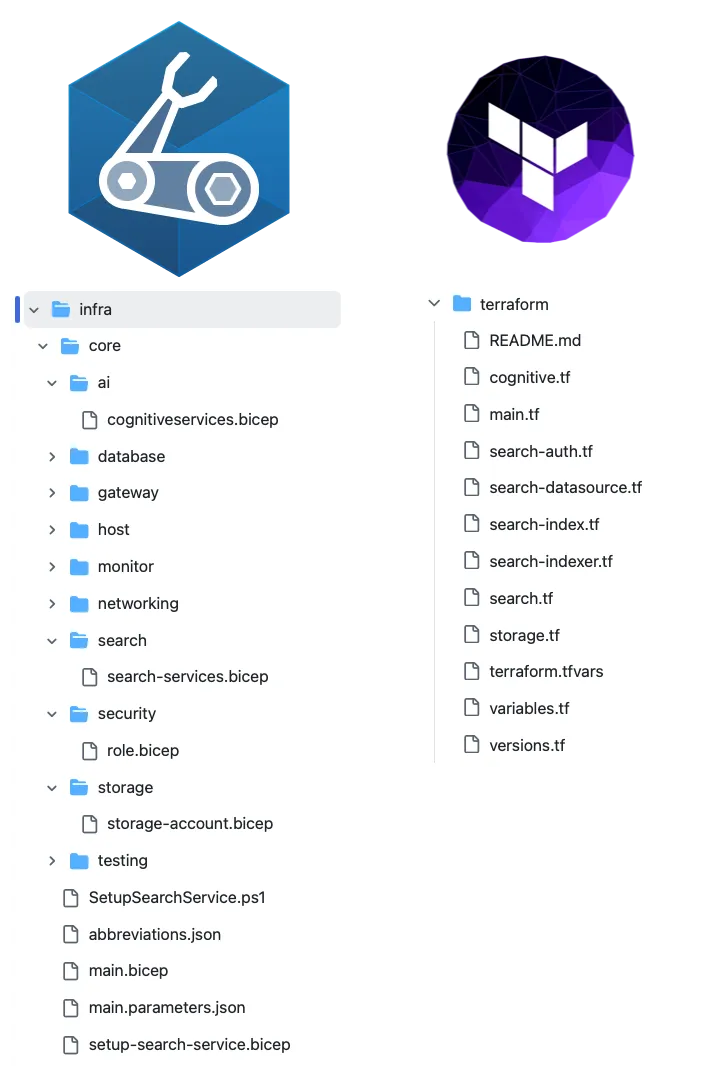
The key differences in the Infrastructure-as-code solutions boil down to two primary reasons:
- Bicep’s root module interface is consolidated into a single file
main.bicepfile Terraform’s (by convention is distributed across three files:main.tf,variables.tfandversions.tf) - Bicep uses a PowerShell script embedded within a
Microsoft.Resource\deploymentScriptsresource in order to make the REST API calls to the Azure Search Service to setup the Index, Data Source and Indexer. This results in the deployment being split between client-side (Bicep) and server-side (PowerShell script running as a Deployment Script). In contrast, Terraform uses two utility providersexternalandhttpin order to obtain a bearer token and make the REST API calls. This means the entire deployment is completed entirely on the local machine.
While the Terraform azurerm provider currently lacks built-in resources for Index, Data Source, and Indexer, it is only a matter of time before these are supported. For this to happen, the Azure Search REST API calls need to be wrapped in a Go SDK (likely the Azure SDK for Go), followed by the creation of Terraform resources and data sources in the azurerm provider using Go. Until then, the Terraform http provider serves as a viable workaround, making complex integrations like this significantly more manageable.
The Need for a Standardized Automation Approach
Azure PMs should ensure that their services adhere to a Definition of Done that includes support for common automation workflows beyond just the Azure Portal experience. Every Azure service and feature should implement CLI and Infrastructure-as-Code (IaC) automation options, ensuring parity between Azure CLI, Azure PowerShell, Bicep, and Terraform. By maintaining this rigor and discipline, Microsoft can provide customers not just with an expedient on-ramp for spinning meters but also a sustainable, long-term operational model.
Successful cloud operations depend on robust Infrastructure-as-Code practices, ensuring that environments remain manageable, repeatable, and resilient over time. Which is why services like Azure Search Service should not go to market until they meet a bare minimum requirements for automation via CLI and Infrastructure-as-Code tools!
Conclusion
The goal of simplifying Azure development should not come at the cost of obscuring the actual tools and processes required to perform a task. Abstraction for the sake of perceived simplicity can inadvertently discourage teams from adopting an automation-first approach.
Instead of applying a cosmetic fix to complexity, the real solution lies in ensuring that services and automation workflows are designed with Infrastructure-as-Code and long-term maintainability in mind. This means addressing inefficiencies at their core rather than layering additional tools on top to mask them.
By embracing direct, transparent automation practices, we can enable customers to build sustainable cloud environments that are operationally sound, rather than just easy to get started with. Hopefully, this example helps to highlight that need, encouraging a shift towards more thoughtful and disciplined engineering approaches across Azure services.
While azd aims to simplify Azure development, I found that in this case, it abstracted away complexity without reducing it. Underneath the convenience commands, the solution was still a mix of Bicep, PowerShell, and Azure Deployment Scripts, making it more cumbersome than necessary.
By rewriting the solution in pure Terraform, I was able to achieve a more streamlined approach that is easier to read, maintain, and extend. Hopefully, this serves as an example of how Microsoft’s open-source solutions can continue evolving towards greater simplicity and clarity. In the meantime, I’ve submitted a Pull Request to the original repository with my Terraform-based implementation — hopefully, others will find it useful!